1 课程回顾 🔗
通过上节课的学习,我们了解了如何在 Emacs 控制窗口的行为,它能进一步的提升我们使用 Emacs 的顺滑度和工作效率。
今天我们来学习如何在 Emacs 里管理单词。
2 场景描述 🔗
我们通过前面的系列课程,可以看到在日常的工作和生活中,我们可以通过 Emacs 来:
- 管理邮件
- 看 RSS 新闻
- 写文档
- 看文档
- 读书(待更新)
- …
而英文恰恰是我们过不去的坎。既然 Org mode 是我们学习、工作、生活的文本系统,那对英语的学习,尤其是其中的基础——单词,是否也可以通过 Org mode 来管理呢?
答案当然是可以的。实际上,我们可以在 emacs-china论坛 找到很多英语学习、单词管理的贴子和插件,这里,我仅仅对我自己喜欢的工作流做一个分享。
我对单词的管理非常简单:
- 遇到生词,能快速通过简约的词典了解其中文含义,进一步地,如果想了解的更多,应该有更详细和复杂的释义。
- 如果我想把这个单词记下来,那就通过 Org Capture 的机制把它记下来,时不时翻出来看下。
实际上,随着 AI 技术的发展,AI 的翻译能力愈来愈强大,诸如 ChatGPT 的出现一定会改变人们的工作和学习方式。在写本文的时候,暂且不考虑 AI 带来的变化。后续我将单独写一篇 ChatGPT 与 Emacs。
3 查单词 🔗
3.1 简单查询 🔗
简单查询,顾名思义,就是以最快的速度了解这个单词的意思。这里,我使用了懒猫大大的 sdcv 插件,它是一个基于本地 stardict 词典的客户端,可以快速查询一些单词释义,使用这个包的好处在于:因为是本地,不需要联网;简单快速。
我们先做以下的准备工作:
- 安装 sdcv 命令行工具:
brew install sdcv - 【可选】安装 mpv 命令行工具,用来朗读单词:
brew install mpv - 到 这里 下载需要的词典,并将词典存放在某个位置,这里我的路径是
~/Backup/stardict/ - 在
~/.zshrc里配置环境变量STARDICT_DATA_DIR的值:export STARDICT_DATA_DIR="$HOME/Backup/stardict"
然后我们来安装这个插件,并将主要的命令 sdcv-search-pointer+ 函数绑定为 C-, ,你也可以按照自己的喜好来绑定快捷键:
;; 这个插件依赖于 `posframe' 这个插件
(use-package posframe
:ensure t
)
(use-package sdcv
:quelpa (sdcv :fetcher github :repo "manateelazycat/sdcv")
:commands (sdcv-search-pointer+)
:bind ("C-," . sdcv-search-pointer+)
:config
(setq sdcv-say-word-p t)
(setq sdcv-dictionary-data-dir (expand-file-name "~/Backup/stardict/"))
(setq sdcv-dictionary-simple-list
'("懒虫简明英汉词典"
"懒虫简明汉英词典"))
(setq sdcv-dictionary-complete-list
'("朗道英汉字典5.0"
"牛津英汉双解美化版"
"21世纪双语科技词典"
"quick_eng-zh_CN"
"新世纪英汉科技大词典"))
(setq sdcv-tooltip-timeout 10)
(setq sdcv-fail-notify-string "没找到释义")
(setq sdcv-tooltip-border-width 2)
)
注:sdcv 在 melpa 上的版本和懒猫大大的版本不是同一个,我用的是懒猫的版本,所以需要用 quelpa 来安装。
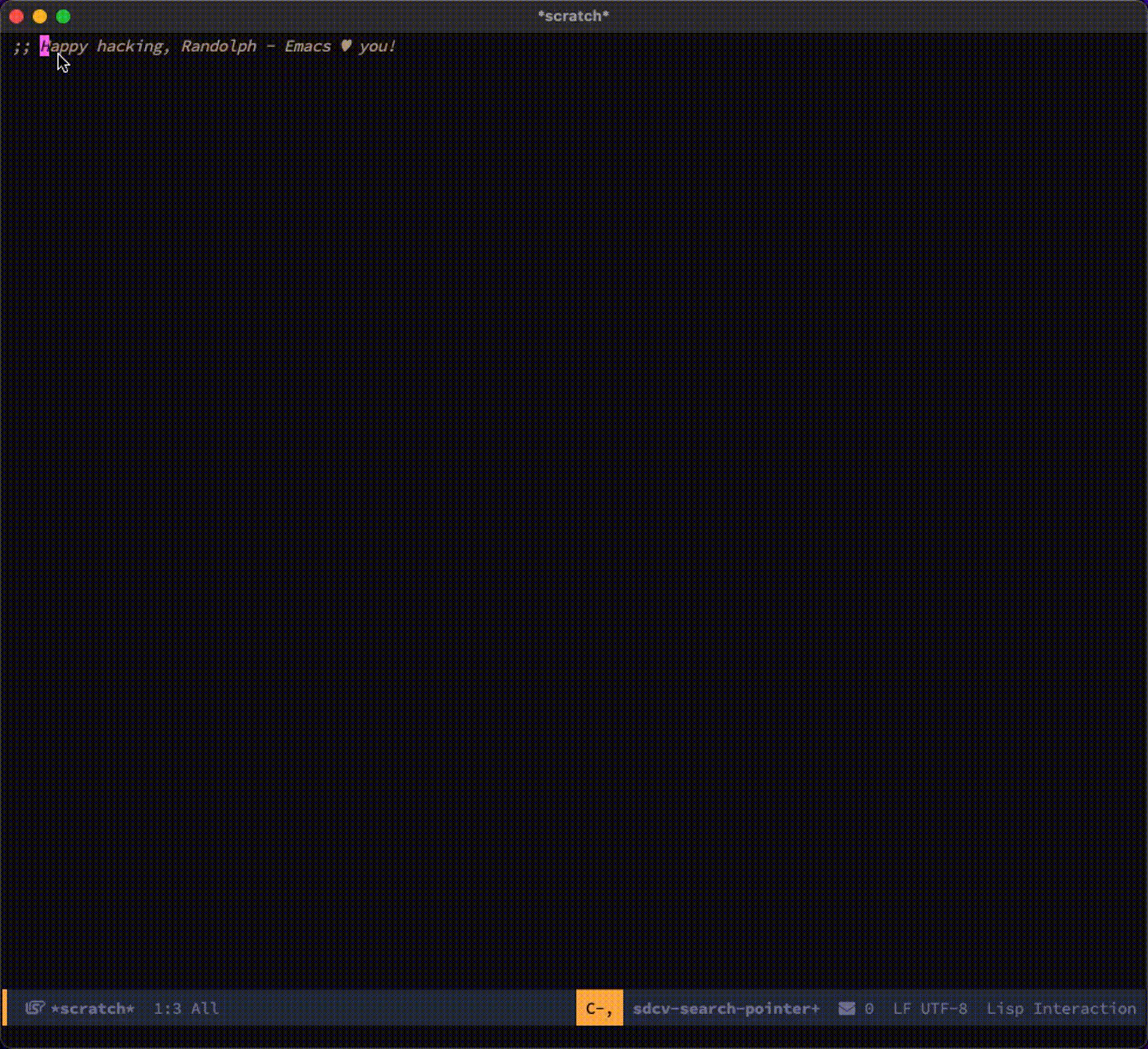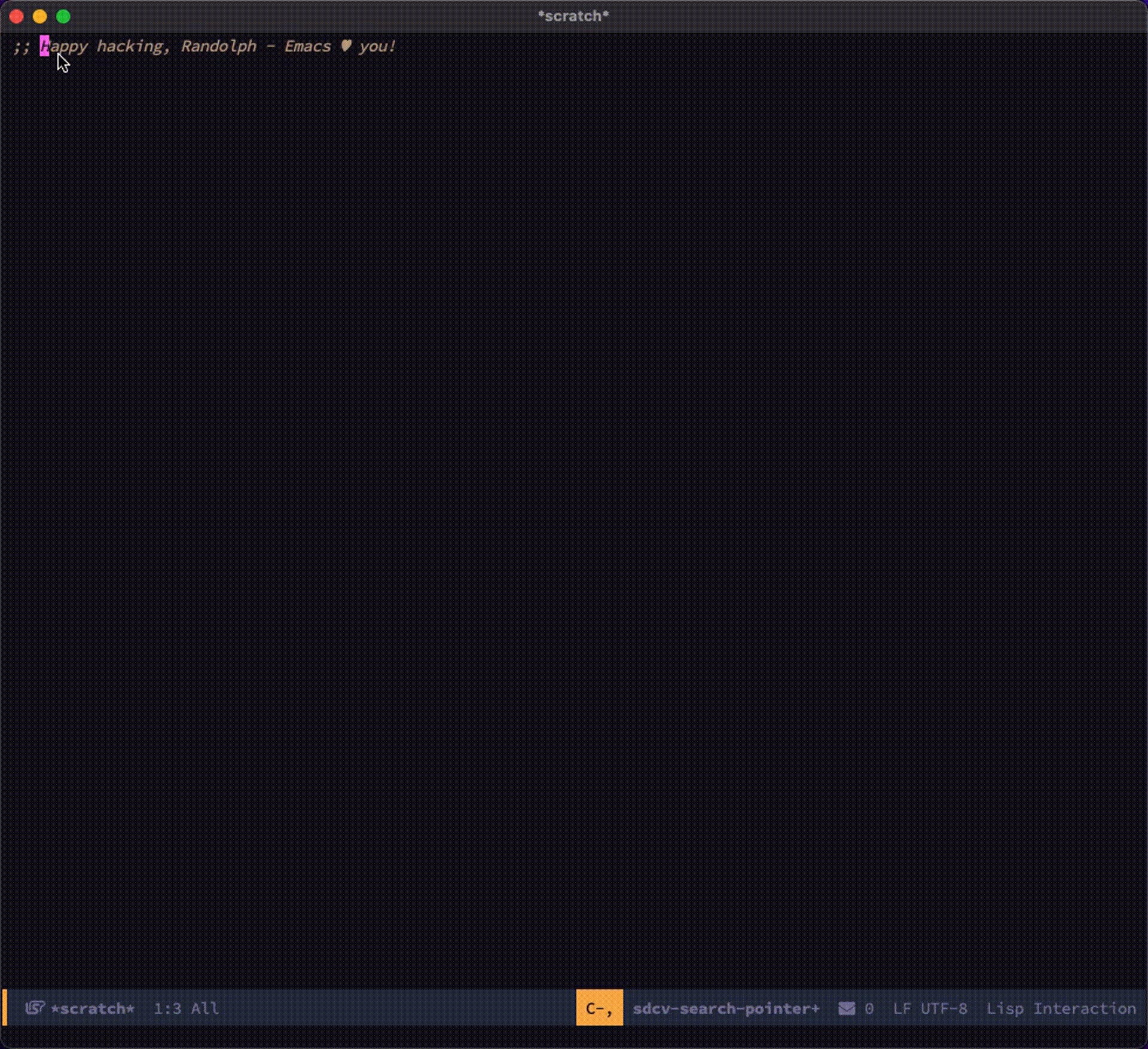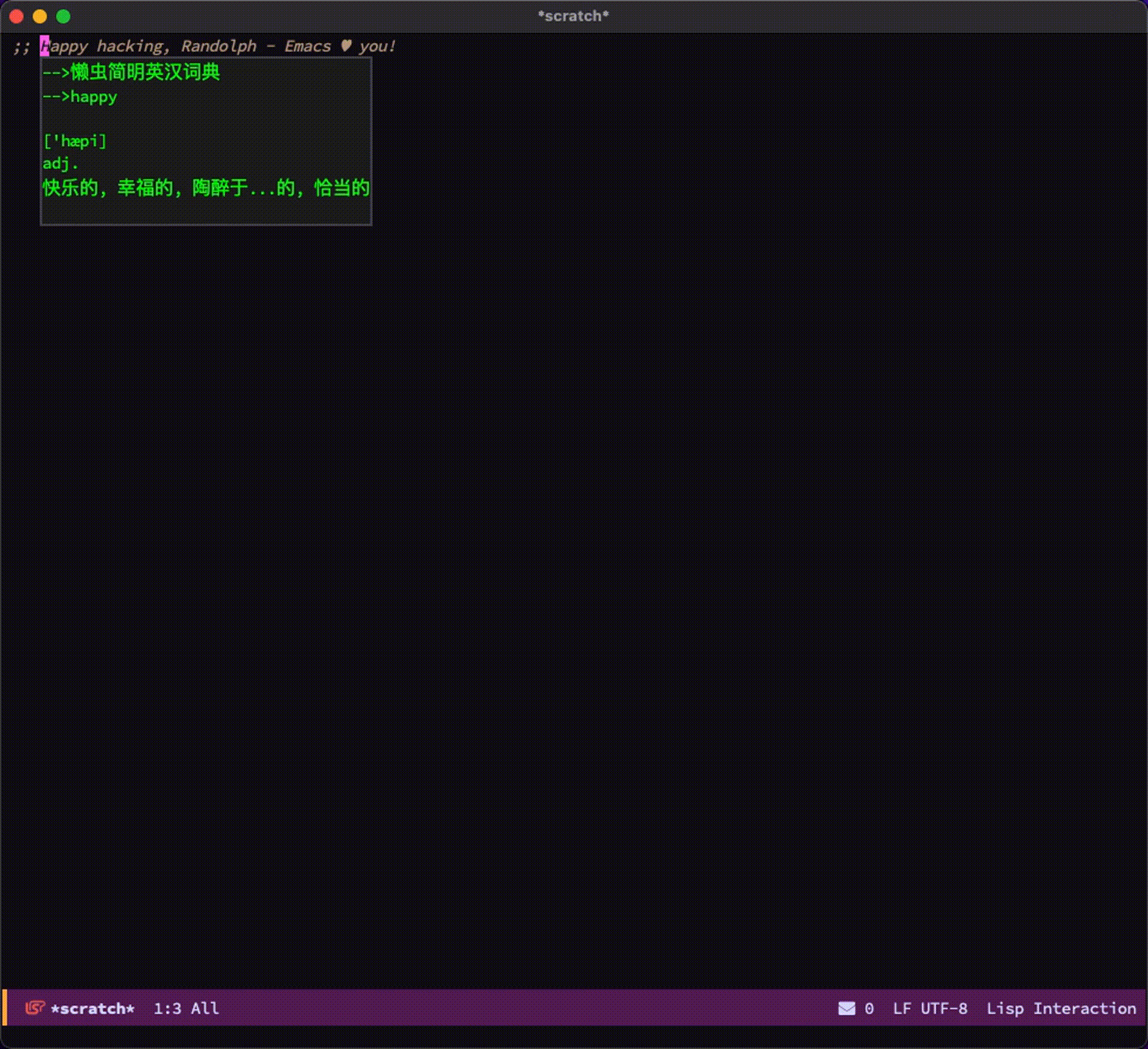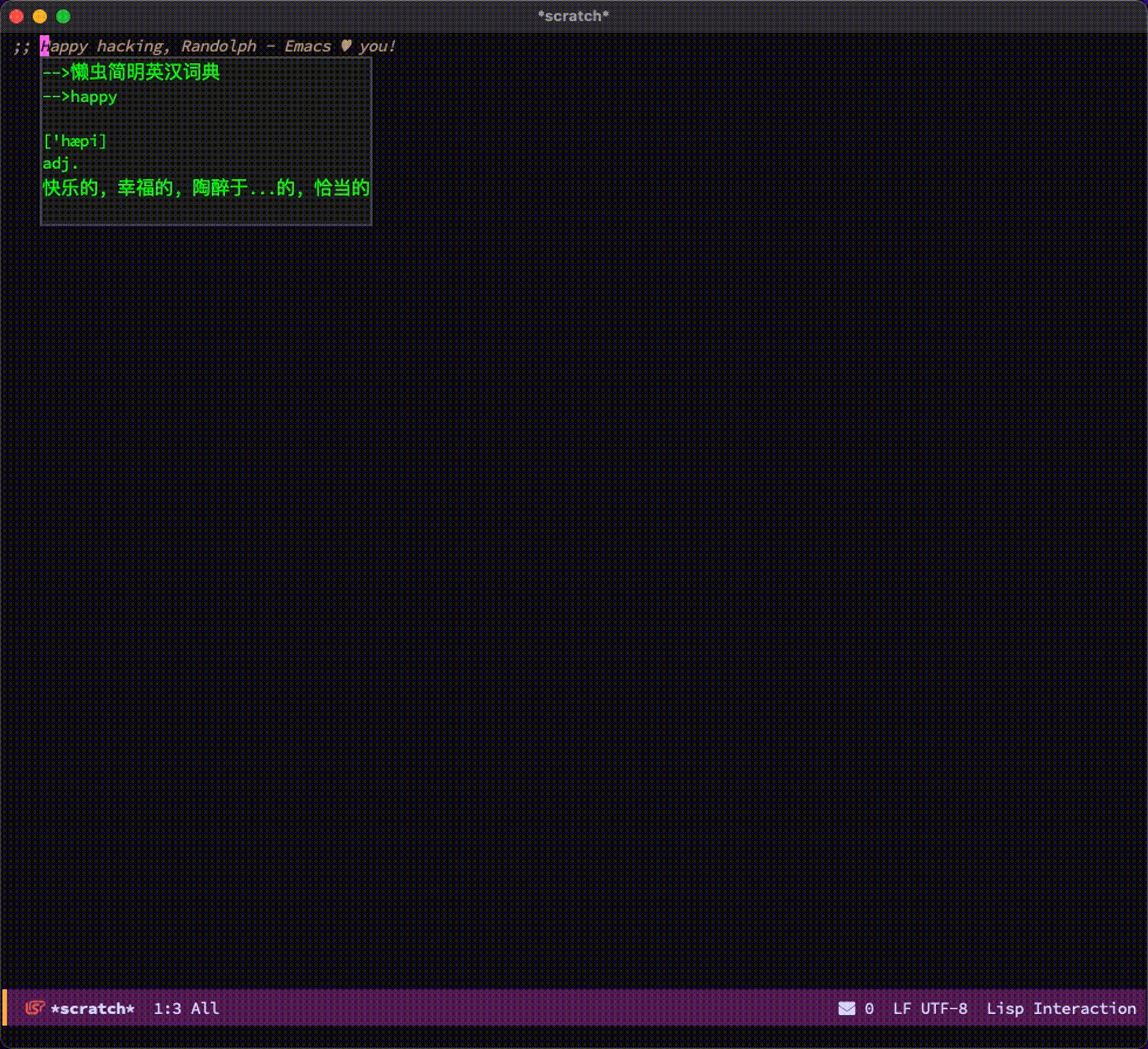
安装完后,我们就可以将光标放到生词上,按下 C-, 命令来快速查看单词的释义啦。
3.2 复杂查询 🔗
当我们需要对单词的释义进行详细的查看,如:同义词、例句、词根等信息时,此时可以使用另外一个插件来解决:fanyi 插件,它是一个线上的多词典系统。
我们来安装和配置它,这里我把调用的快捷键绑定到了 ESC-ESC = w 上,你也可以根据自己的需要进行修改:
(use-package fanyi
:ensure t
:bind-keymap ("\e\e =" . fanyi-map)
:bind (:map fanyi-map
("w" . fanyi-dwim2)
("i" . fanyi-dwim))
:init
;; to support `org-store-link' and `org-insert-link'
(require 'ol-fanyi)
;; 如果当前指针下有单词,选择当前单词,否则选择剪贴板
(with-eval-after-load 'org-capture
(add-to-list 'org-capture-templates
'("w" "New word" entry (file+olp+datetree "20221001T221032--vocabulary__studying.org" "New")
"* %^{Input the new word:|%(cond ((with-current-buffer (org-capture-get :original-buffer) (thing-at-point 'word 'no-properties))) ((clipboard/get)))}\n\n[[fanyi:%\\1][%\\1]]\n\n[[http://dict.cn/%\\1][海词:%\\1]]%?"
:tree-type day
:empty-lines 1
:jump-to-captured t)))
:config
(defvar fanyi-map nil "keymap for `fanyi")
(setq fanyi-map (make-sparse-keymap))
(setq fanyi-sound-player "mpv")
:custom
(fanyi-providers '(;; 海词
fanyi-haici-provider
;; 有道同义词词典
fanyi-youdao-thesaurus-provider
;; ;; Etymonline
;; fanyi-etymon-provider
;; Longman
fanyi-longman-provider
;; ;; LibreTranslate
;; fanyi-libre-provider
)))
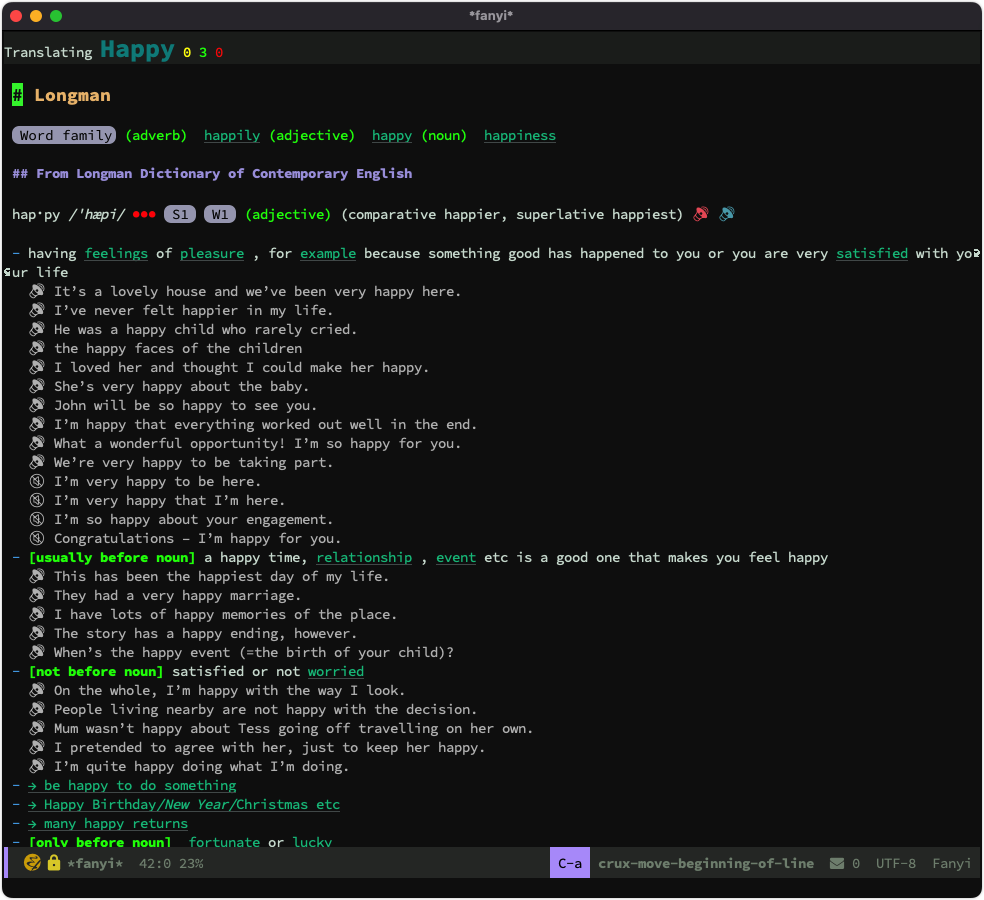
安装完后,我们可以把光标移动到生词上,按下 ESC-ESC = w 来查看释义:
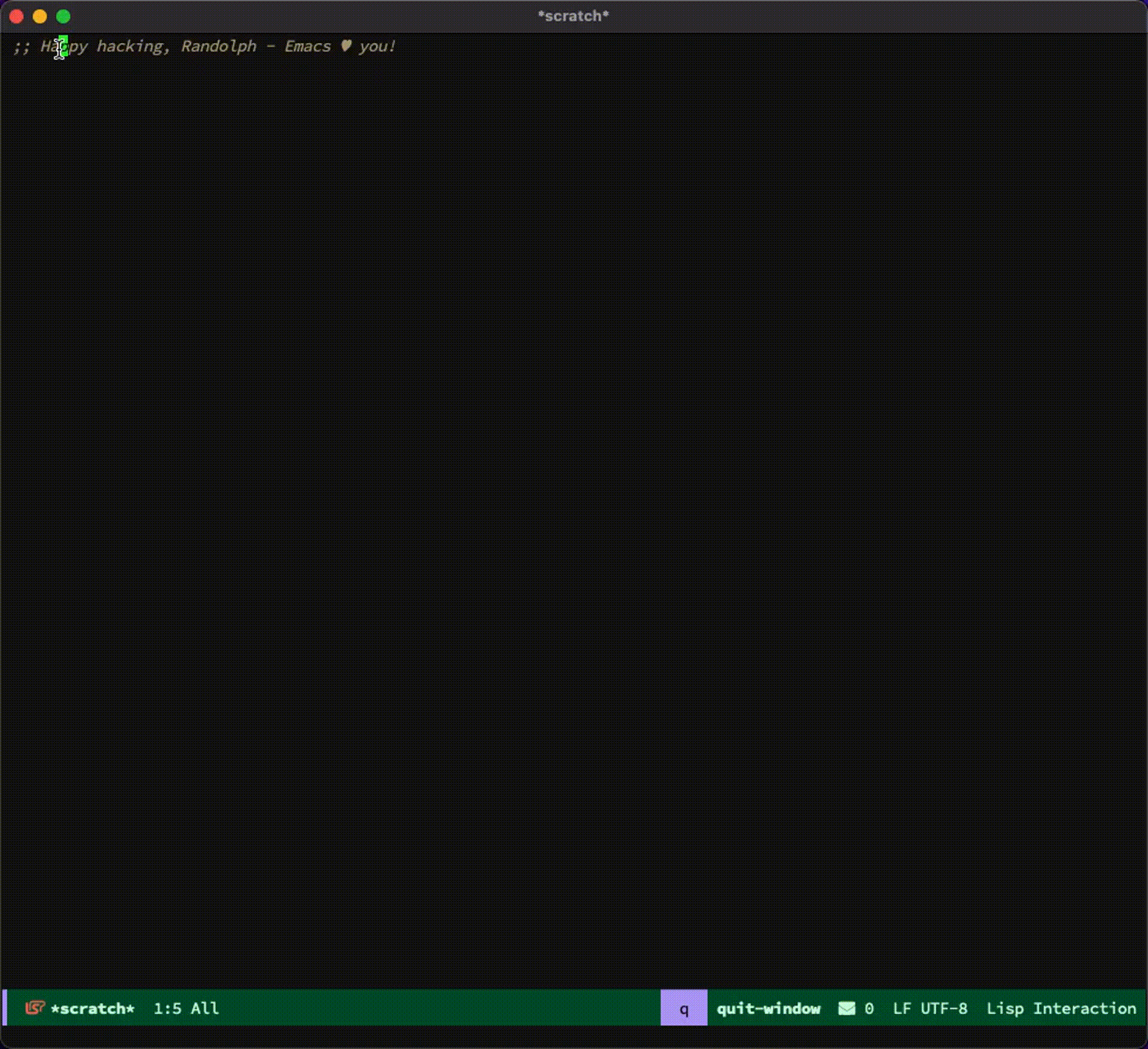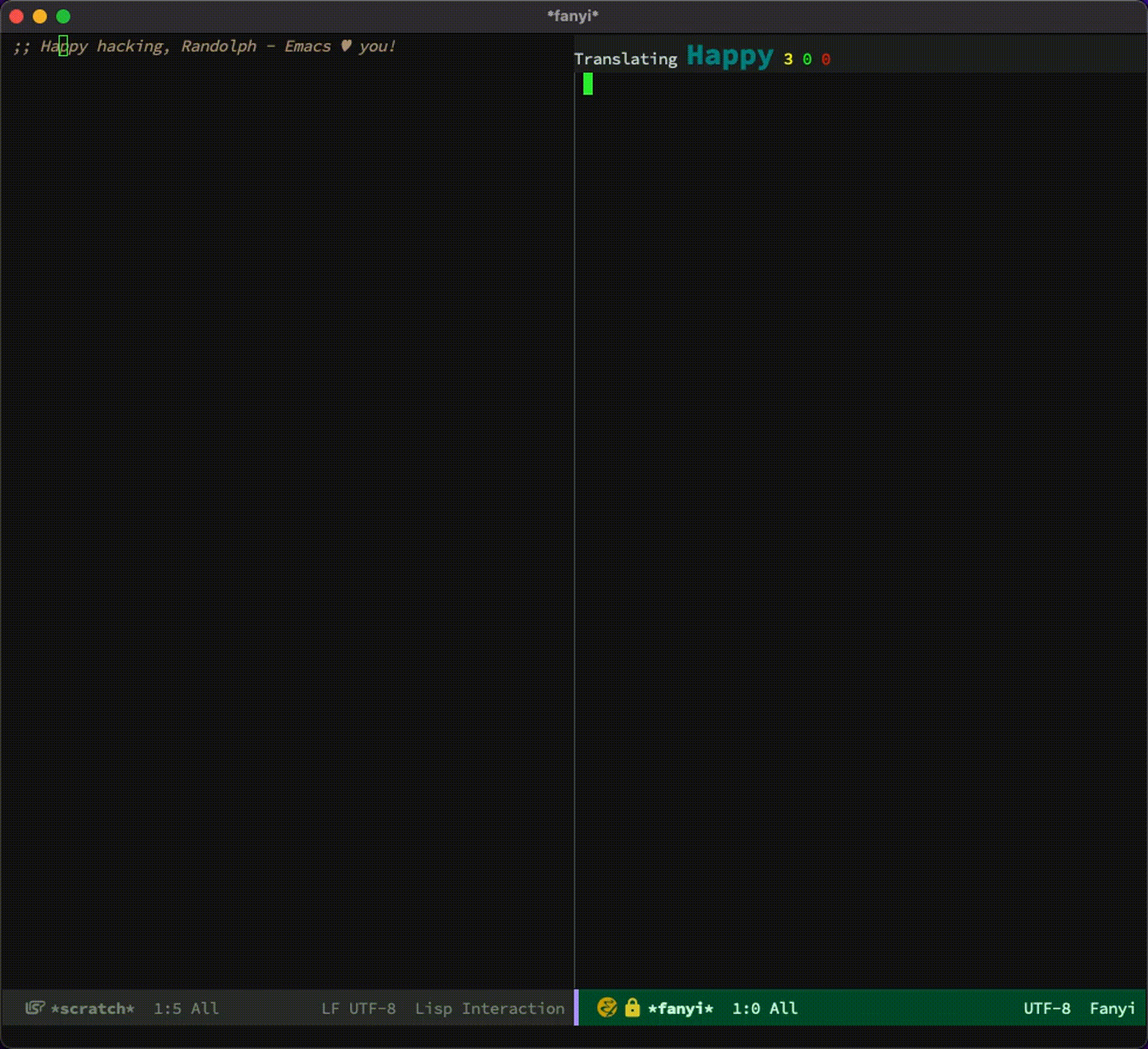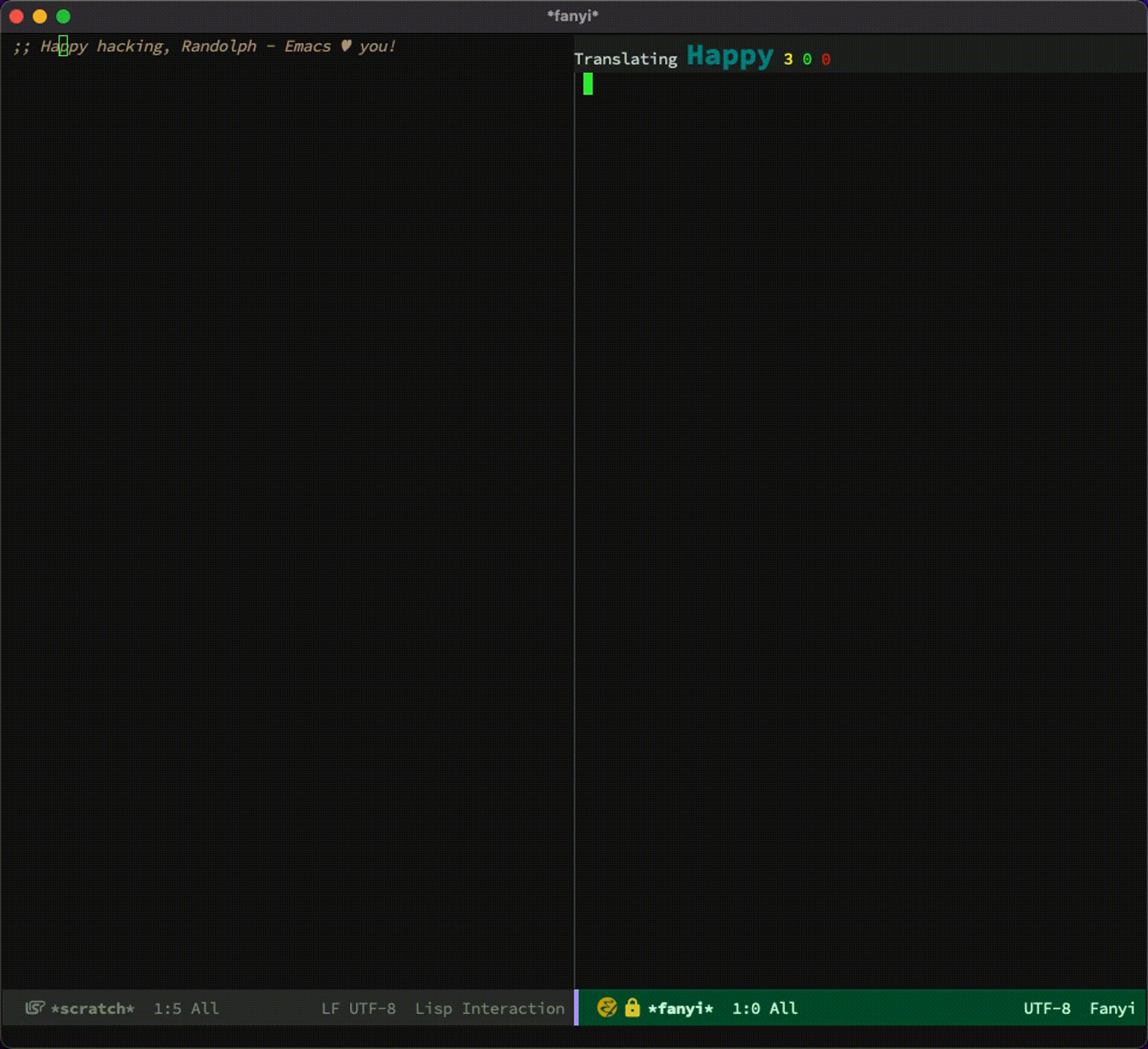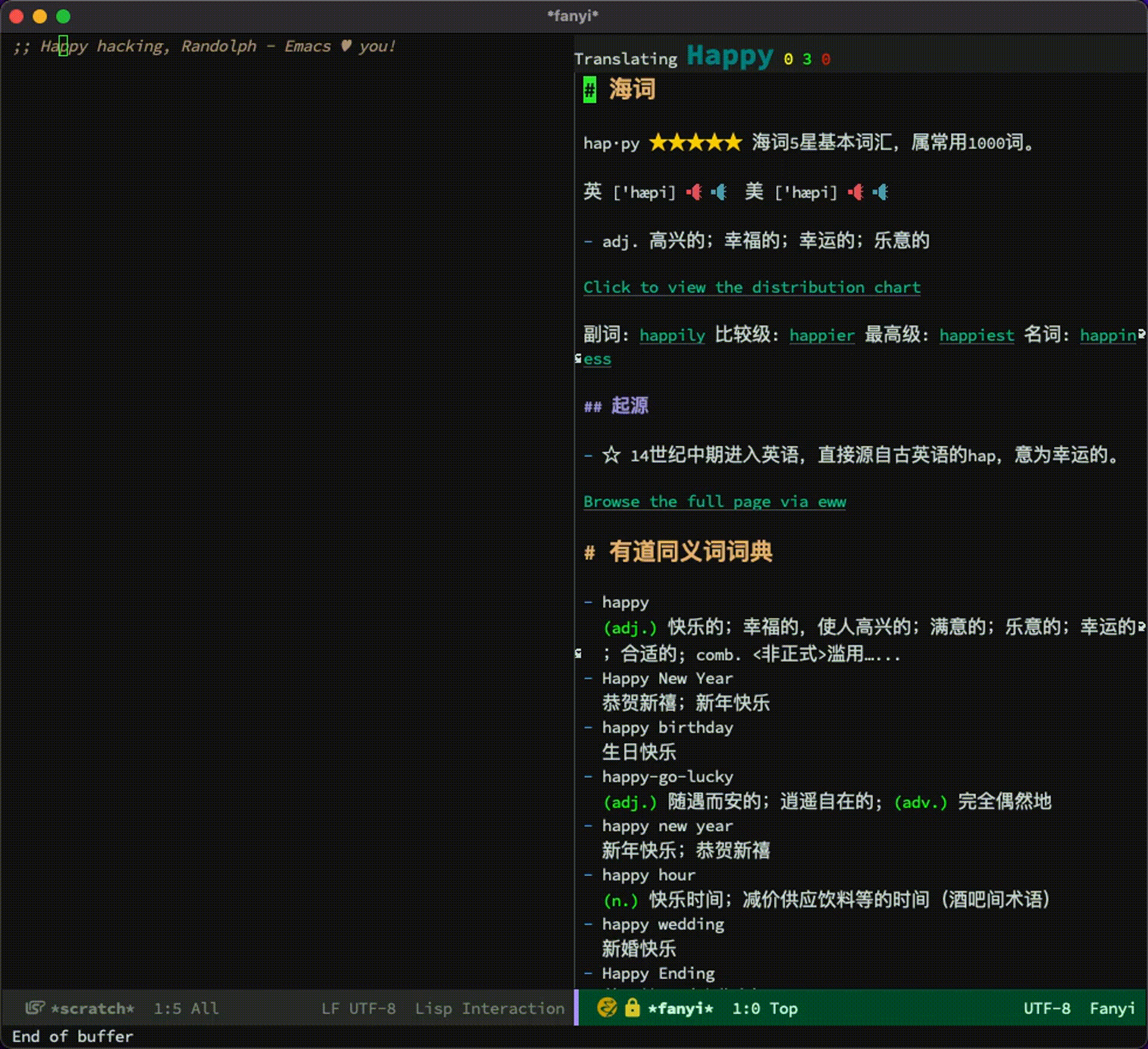
其中朗文词典的读音非常棒:
 海词还能看到释义分布图:
海词还能看到释义分布图:
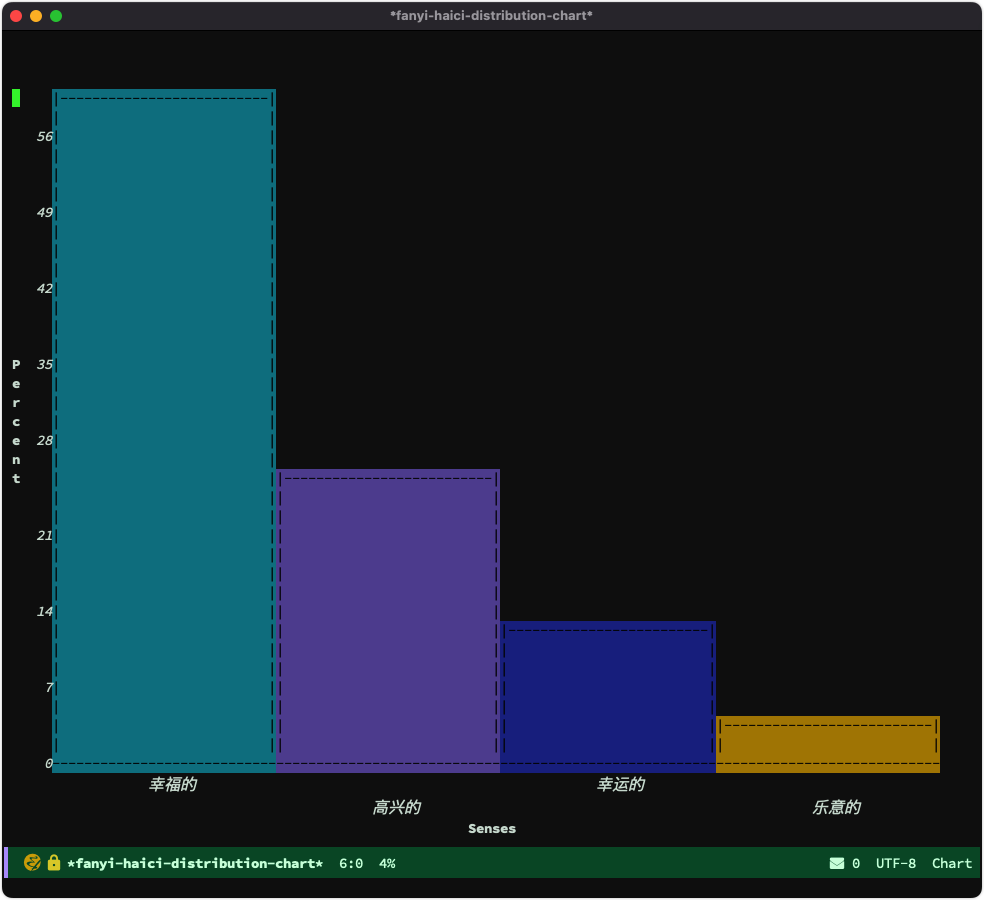
除了比较慢外,堪称完美。
4 记录单词 🔗
我们了解了在 Emacs 里如何查单词,那么是否可以记录一套自己专属的生词本呢?答案当然是可以的,毕竟 Emacs 无所不能!
我们利用 Org mode 的 Capture 机制来实现这一点。在 fanyi 插件的配置中,有这么一段代码,它的作用就是设置一个 Org Capture 的模板以及快捷键。
;; 如果当前指针下有单词,选择当前单词,否则选择剪贴板
(with-eval-after-load 'org-capture
(add-to-list 'org-capture-templates
'("w" "New word" entry (file+olp+datetree "20221001T221032--vocabulary__studying.org" "New")
"* %^{Input the new word:|%(cond ((with-current-buffer (org-capture-get :original-buffer) (thing-at-point 'word 'no-properties))) ((clipboard/get)))}\n\n[[fanyi:%\\1][%\\1]]\n\n[[http://dict.cn/%\\1][海词:%\\1]]%?"
:tree-type day
:empty-lines 1
:jump-to-captured t)))
根据前置课程,这段代码的含义如下:
- 按下
ESC-ESC c w来调起记录生词的界面; - 如果当前光标下有单词,默认选的是当前光标下的单词;若当前光标下没有单词,则选择剪贴板里的单词;
- 记录后有两个链接,一个是
fanyi的链接,打开后将直接跳转到fanyi插件的这个单词的页面;另一个是海词的网页链接,方便导出时使用; - 所有的单词会记录到
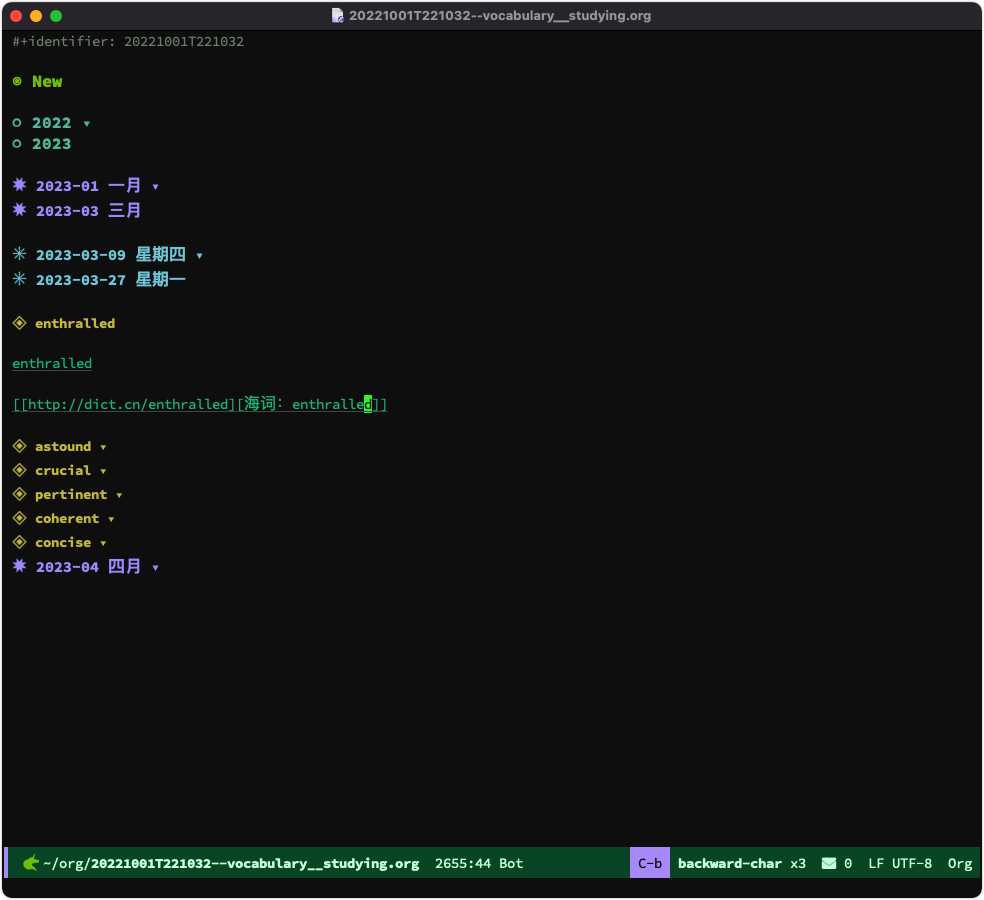
20221001T221032--vocabulary__studying.org这个文件,以日期的方式组织。
这里的 clipboard/get 函数,是获取系统剪贴板内容的函数,代码如下:
;; 从剪贴板获取内容
(defun clipboard/get ()
"return the content of clipboard as string"
(interactive)
(with-temp-buffer
(clipboard-yank)
(buffer-substring-no-properties (point-min) (point-max))))
整个过程如下:
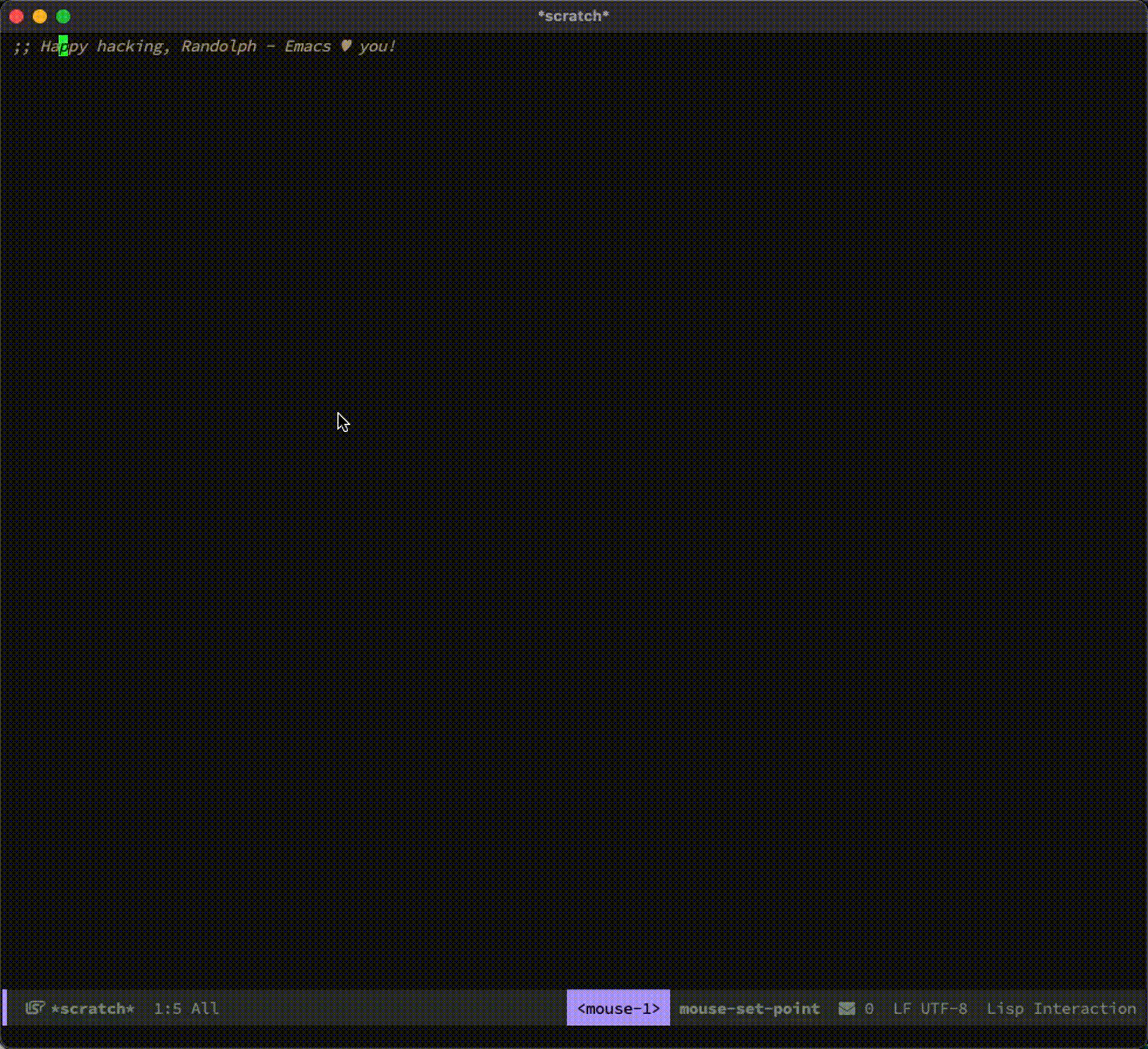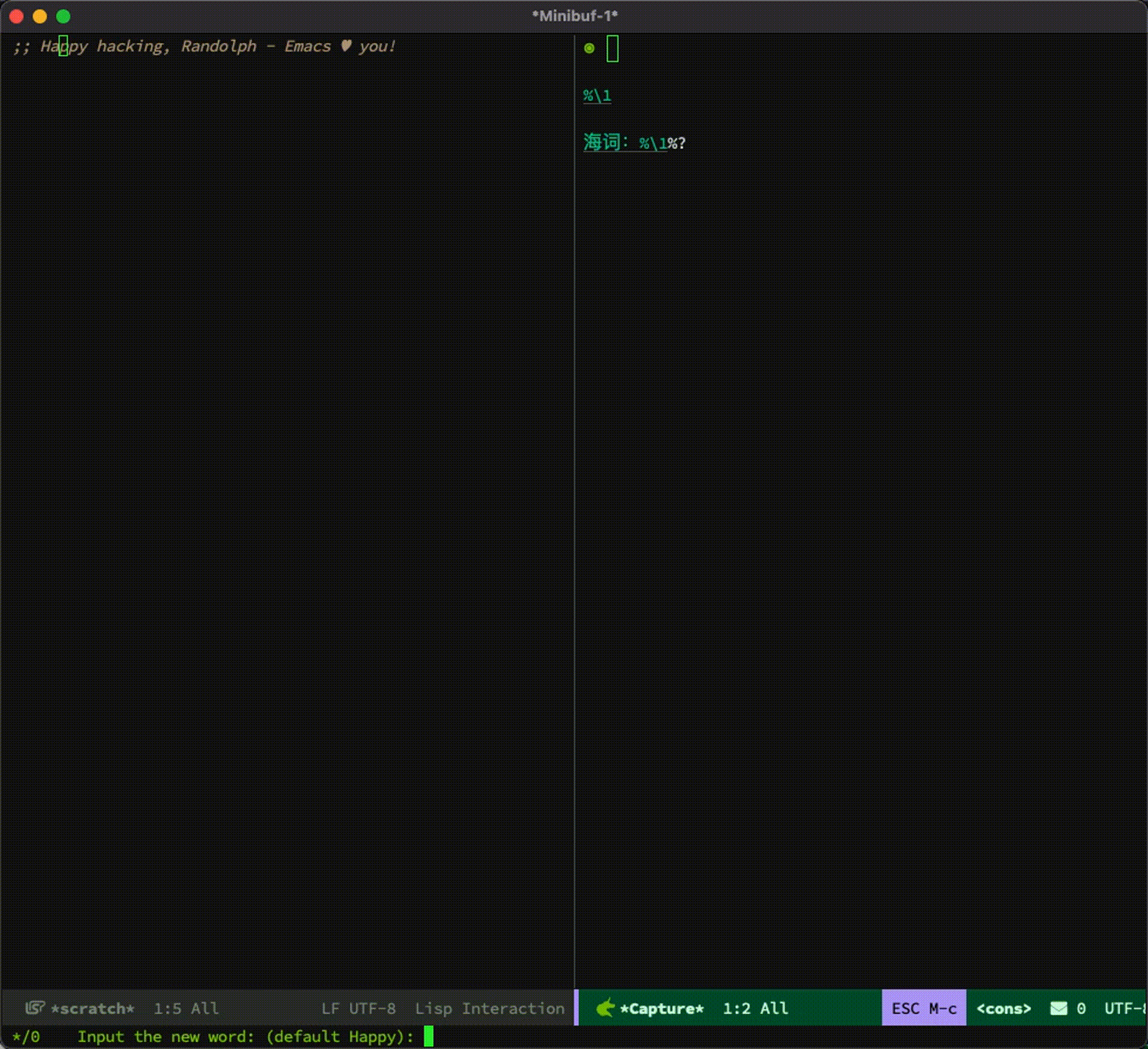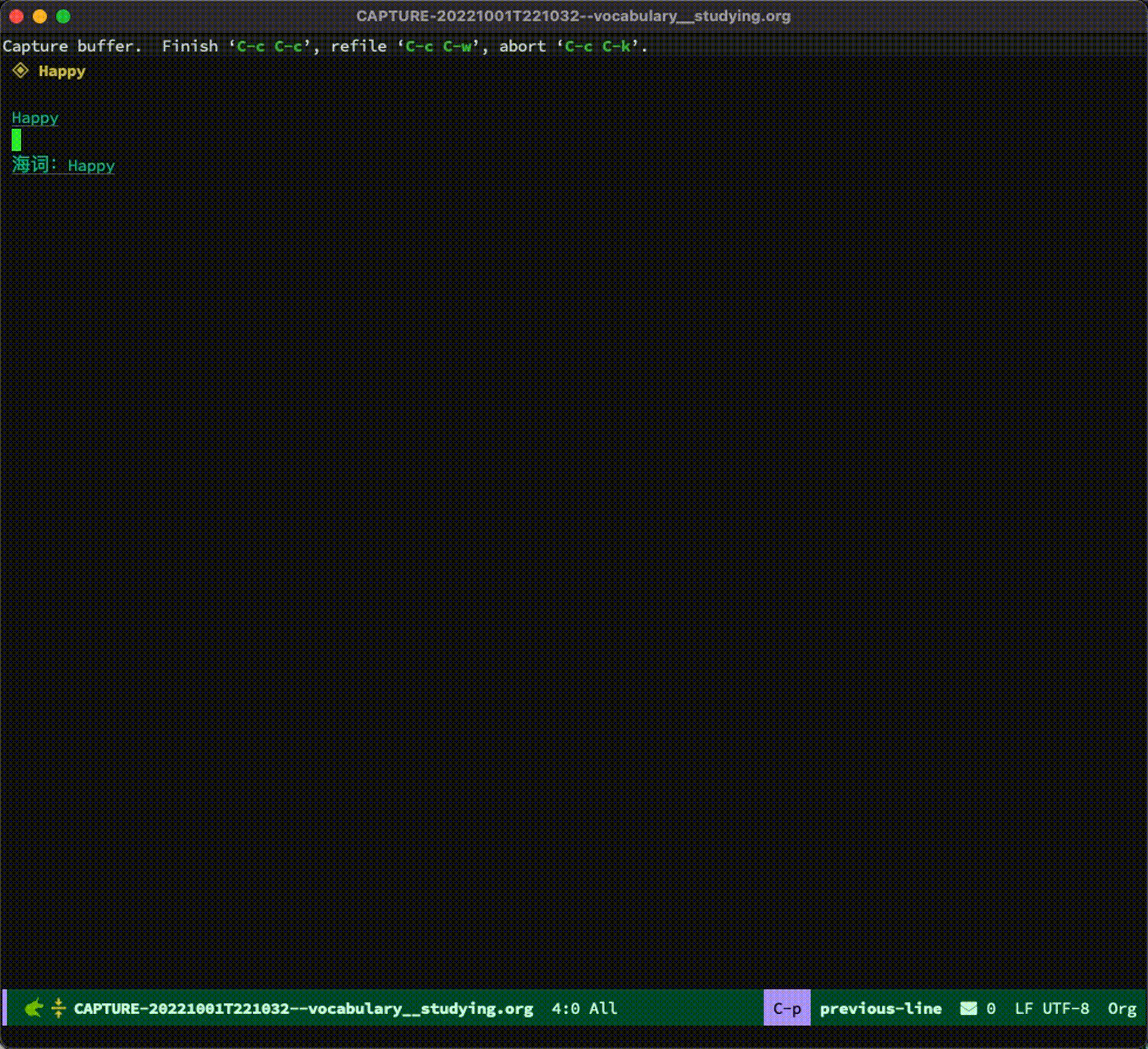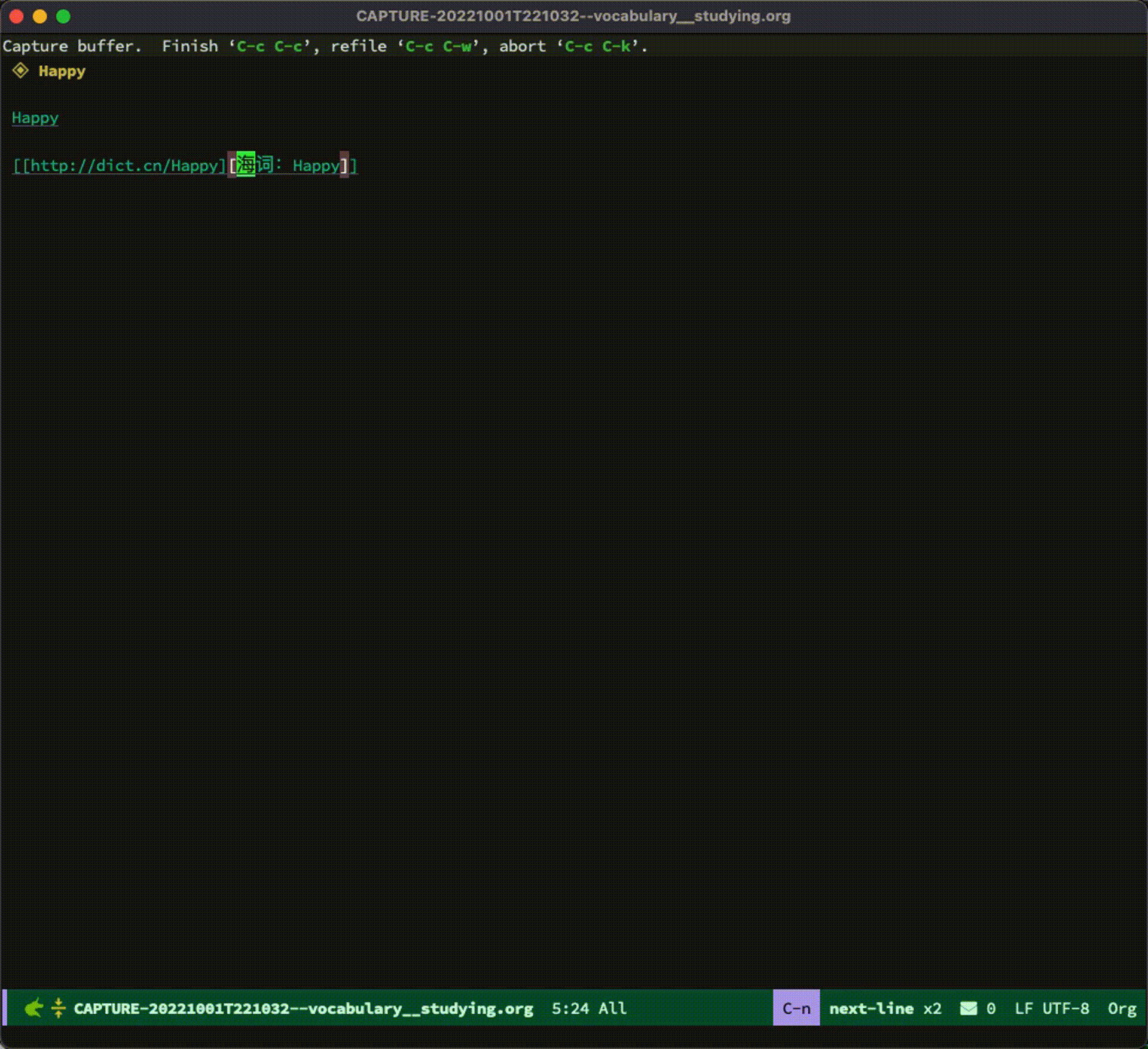
最后的生词本大概长下面这样:
5 结语 🔗
通过今天的课程,我们学习了如何在 Emacs 里处理单词,如何进行简单查询、复杂查询,如何记录生词并管理生词本。而生词本作为人生持续学习的内容之一,通通可以纳入到 Org mode 的体系进行管理和查阅,非常方便。
当然随着科技的发展,生词、翻译将逐渐被 AI 攻克,到未来的某一天,英语已经不再是问题(现在的 ChatGPT 的翻译效果堪称接近人类),到那时,也许我们对于单词的学习和管理也将发生变化。
这节课的配置文件的快照见:emacs-config-l25.org
你也可以在 这里 查看最新的配置文件。